Text Analysis
Wordview provides an overview of your text data, as well as general statistics and different
distributions and plots via TextStatsPlots class. To get started, import and
instantiate an object of TextStatsPlots using your dataset:
import pandas as pd
from wordview.text_analysis import TextStatsPlots
imdb_train = pd.read_csv("data/IMDB_Dataset_sample.csv")
ta = TextStatsPlots(df=imdb_train, text_column='review')
Overview
Use the show_stats method to see a set of different statistics about
of your dataset.
ta.show_stats()
┌───────────────────┬─────────┐
│ Language/s │ EN │
├───────────────────┼─────────┤
│ Unique Words │ 48,791 │
├───────────────────┼─────────┤
│ All Words │ 666,898 │
├───────────────────┼─────────┤
│ Documents │ 5,000 │
├───────────────────┼─────────┤
│ Median Doc Length │ 211.0 │
├───────────────────┼─────────┤
│ Nouns │ 28,482 │
├───────────────────┼─────────┤
│ Adjectives │ 19,519 │
├───────────────────┼─────────┤
│ Verbs │ 15,241 │
└───────────────────┴─────────┘
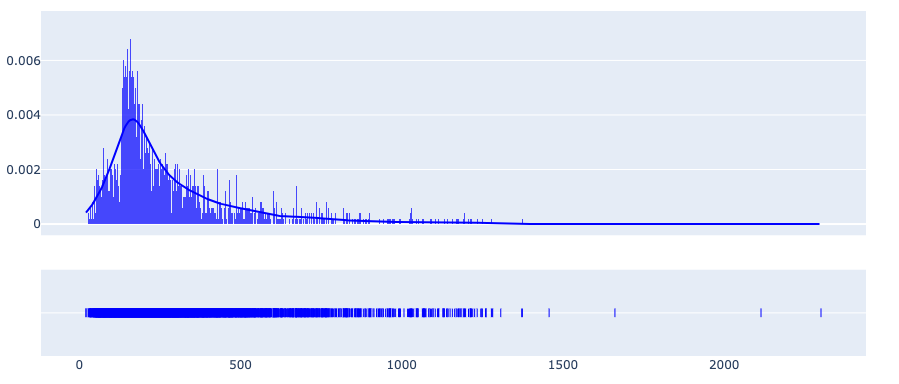
Distributions
You can look into different distributions using the show_distplot
method. For instance, you can see the distribution of document lengths
to decide on a sequence length in sequence models with a fixed input or
when you carry out mini-batch training.
ta.show_distplot(distribution='doc_len')
You can also see the distribution of sentence lengths to make better decisions about semantic composition functions and sentence embeddings.
ta.show_distplot(distribution='sentence_len')
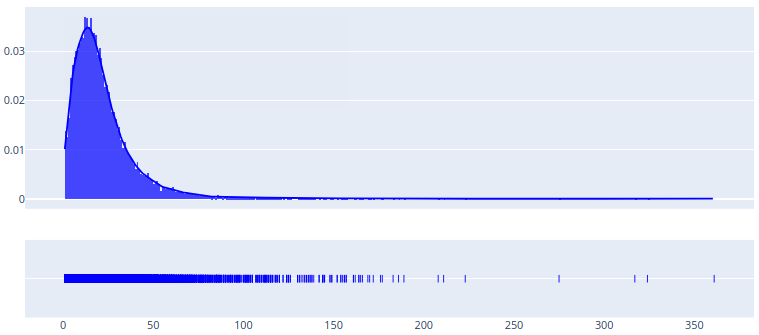
Or, you can see the Zipf distribution of words:
ta.show_distplot(distribution='word_frequency_zipf')
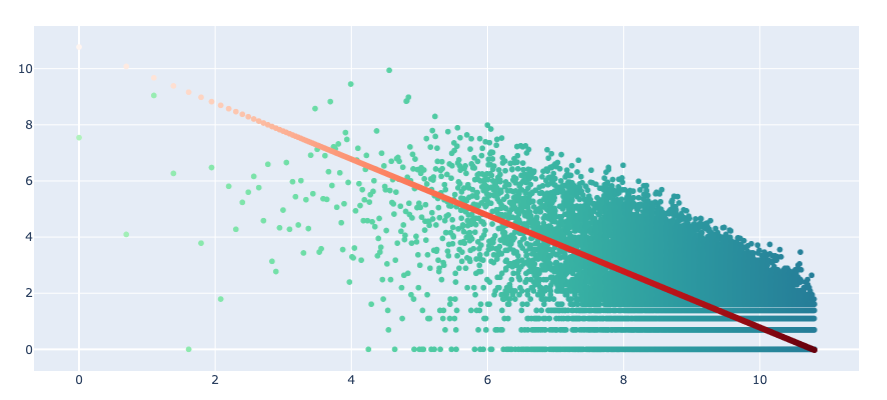
See this excellent article to learn how Zipf’s law can be used to improve some NLP models.
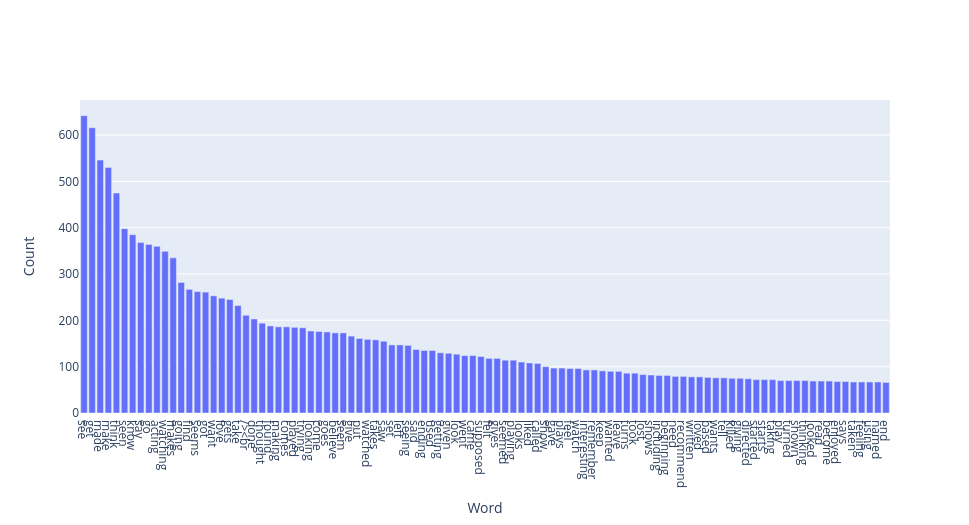
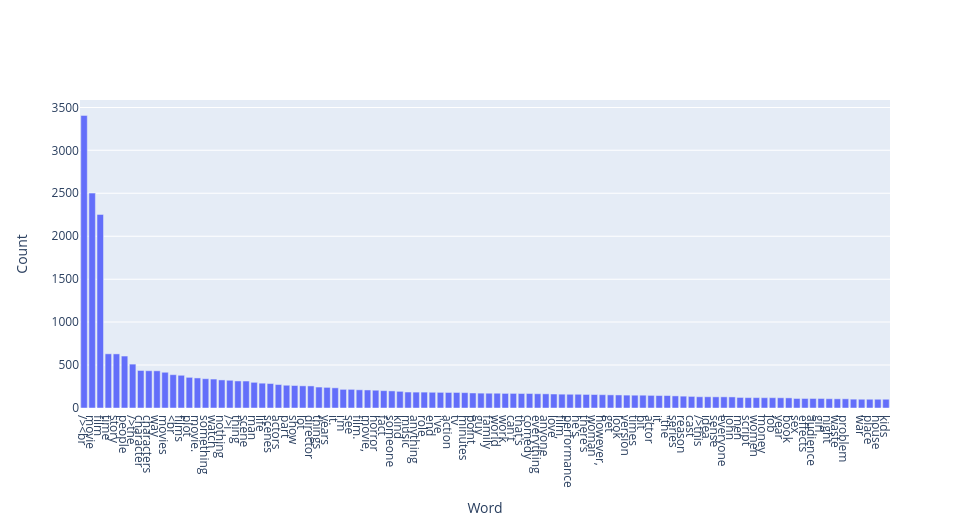
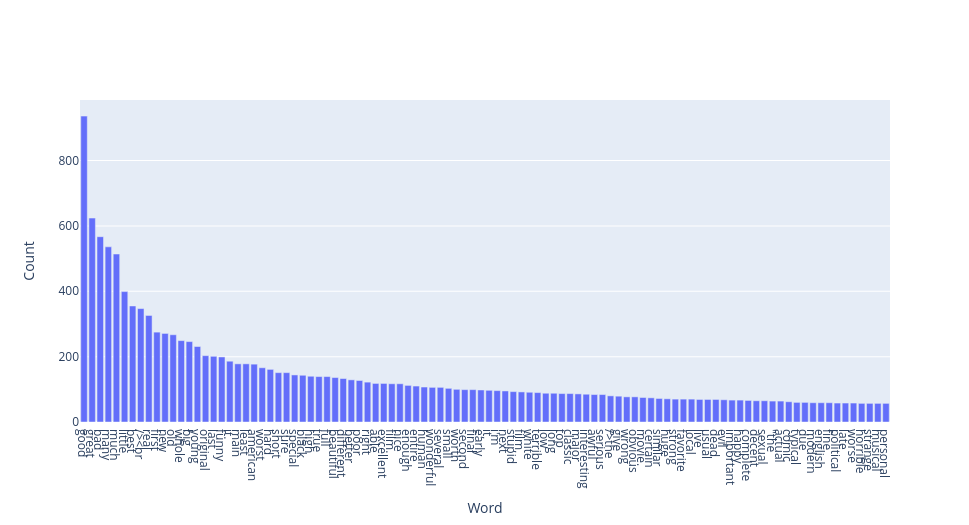
Part of Speech Tags
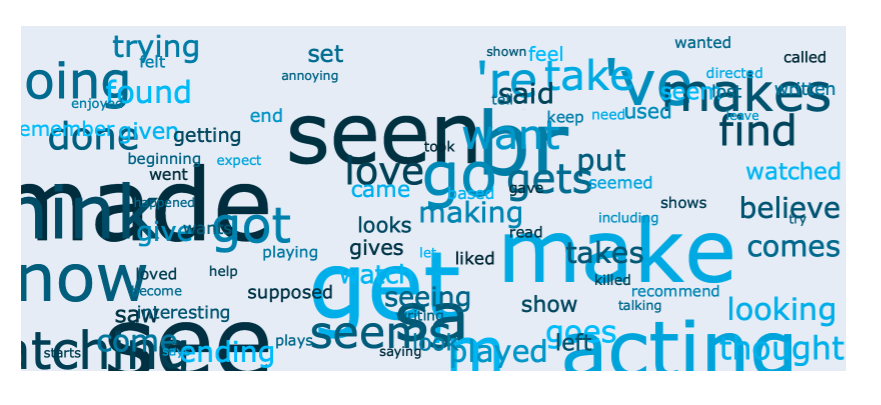
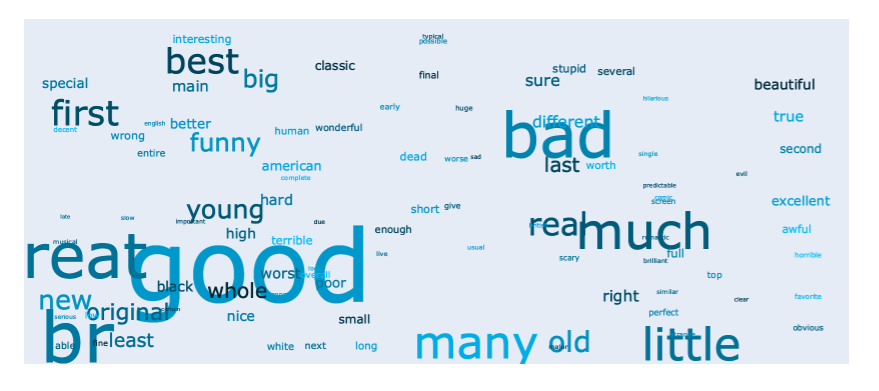
The different Part of Speech tags can be viewed using two methods:
show_word_clouds() and show_bar_plots(). Both methods take a
pos argument, which can be one of the tags in the Penn Treebank
Project <https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html>.
# To see verbs
ta.show_word_clouds(pos="VB")
# To see nouns
ta.show_word_clouds(pos="NN")
# To see adjectives
ta.show_word_clouds(pos="JJ")

# To see verbs
ta.show_bar_plots(pos="VB")
# To see nouns
ta.show_bar_plots(pos="NN")
# To see adjectives
ta.show_bar_plots(pos="JJ")